
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- mysql
- @RequiredArgsConstructor
- 쿼리메소드
- code
- 마크다운 테이블
- WebClient
- JsonNode
- 선형 리스트
- 스택 큐 차이
- 배열
- java
- 연결 리스트
- 내부 정렬
- CleanCode
- 계산 검색 방식
- 자료구조
- @NoArgsConstructor
- @ComponentScan
- 코드
- query
- 인터페이스
- 정렬
- 마크다운
- 빅 오 표기법
- 클린
- 클래스
- 트리
- 클린코드
- 리스트
- 쿠키
- Today
- Total
Developer Cafe
그래프 본문
그래프는 데이터가 어떻게 연결되는지 쉽게 이해시키므로 관계에 특화된 자료구조다.

원 하나를 노드로 그 노드는 정점이라 부르고, 정점간 관계인 선은 간선이라 부른다.
또한 그래프는 트위터 팔로우 기능처럼 화살표로 표현된 것을 방향 그래프,
페이스북처럼 상호작용하는 그래프는 무방향 그래프라한다.
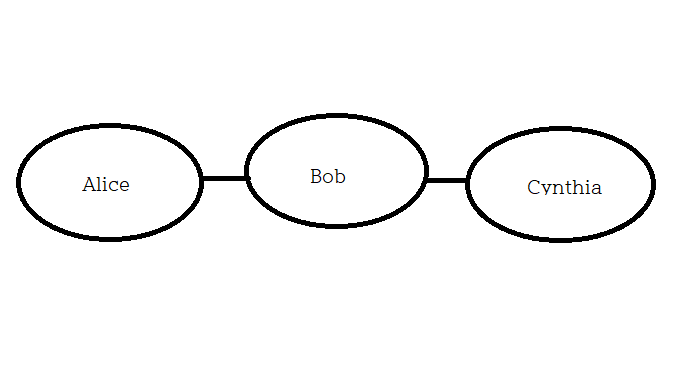
위 그림에서 앨리스는 밥과 직접 커넥션이 있으나 신시아와 직접 커넥션이 없다.
비직접적인 커넥션을 포함해 앨리스 전체 네트워크를 찾으려면 두가지 방법이 있다.
1. 너비 우선 탐색
2. 깊이 우선 탐색
여기선 너비 우선 탐색만 포스팅하고 깊이 우선 탐색은 차후 업데이트하거나 따로 비교포스팅하겠다.
너비 우선 탐색
1. 현재 정점과 인접한 각 정점을 방문한다. 이전에 방문한 적 없는 정점이면 방문했다 표시하고 큐에 추가한다.
(아직 현재 정점으로 바뀐건아님)
2. 이어 다른 인접 정점들 방문 후 큐로부터 현재 정점제거 후 다음 정점을 현재 정점으로 한다.
3. 현재 정점에 인접한 정점을 모두 방문했고 큐에 더 이상 정점이 없으면 알고리즘을 종료한다.
너비 우선 탐색 단계는 삭제단계 방문단계로 나뉘는데
삭제단계는 O(N)이 아니라 O(V)라고 표시한다. 이는 단순히 정점만 처리하는게 아니라 간선도 처리하는 단계를 추가로 포함하기 때문이다.
방문단계는 간선이 E개 일때 2E번 인접한 정점을 확인한다. 결국 너비 우선 탐색의 효율성은 O(V+E)단계 이다.
관계형 데이터베이스 vs 그래프 데이터 베이스 차이
관계형 데이터 베이스에서 친구가 M명일때 각 정보를 가져오는 효율성은 O(M log N)단계이다.
(친구를 찾는 단계는 O(log N) 관계형이니 이진 검색 사용가능!)
(친구 명수에 따라 친구를 찾아야되니 O(log N) * M)
반면 그래프 데이터 베이스에서 친구를 찾을때에는 기준이 되는 사람만 찾으면 친구를 찾을 수 있으므로 한 단계만 걸린다. 각 정점이 모든 정보를 포함하기에 간선을 순회하기만 하면 된다. O(N)
가중 그래프
- 일반적인 그래프와 비슷하지만 간선에 추가 정보가 들어간다는 차이가 있다

'자료 구조 > 누구나 자료 구조와 알고리즘' 카테고리의 다른 글
| 데이크스트라의 알고리즘 (0) | 2021.03.08 |
|---|---|
| 이진 트리 (0) | 2021.03.08 |
| 배열 vs 연결 리스트 차이 그리고 노드, 이중 연결 리스트 (0) | 2021.03.07 |
| 퀵 정렬 vs 삽입 정렬 차이 (0) | 2021.03.07 |
| 재귀 알고리즘 (0) | 2021.03.07 |

